|
Yixuan Li (李奕萱) I am currently a fourth year Ph.D. student at MMLab in Department of Information Engineering, CUHK, advised by Prof. Dahua Lin. Before that, I received my Master's degree from Nanjing University in 2022, supervised by Prof. Limin Wang, and my Bachelor's degree also from Nanjing University in 2019. My research area is World Model, Video Generation and 3D vision, especially 3D Scene Reconstruction and Generation. My previous research interest was video understanding and action recognition. Email / Google Scholar / Twitter / Github |

|
News
• 06/2025 Two papers accepted by ICCV 2025. |
Selected Publications |

|
LingBot-World: Advancing Open-source World Models
Leader of Rendering Data. Technical report, 2026 arXiv / homepage / code LingBot-World is an open-source framework designed for interactive world modeling. At its core, LingBot-World-Base delivers high-fidelity, controllable, and logically consistent simulations. Powered by a Scalable Data Engine, it transcends passive video synthesis by learning physics and causality from massive-scale gaming environments, enabling interaction with generated worlds. |
|
|
CameraAnything: Refilming Videos with Arbitrary Camera Control
Yixuan Li*, Yanhong Zeng*, Ka Leong Cheng, Jiayi Zhu, Hanlin Wang, Wen Wang, Yihao Meng, Hao Ouyang, Qiuyu Wang, Yue Yu, ZiDong Wang, Yiyuan Zhang, Yujun Shen, Dahua Lin. ECCV, 2026 CameraAnything is a unified framework for video camera motion editing with joint control over intrinsic and extrinsic camera parameters, enabling arbitrary viewpoint control, focal length adjustment, resolution adaptation, and multi-shot pose transitions within a single generation process. |
|
|
Multi-identity Human Image Animation with Structural Video Diffusion
Zhenzhi Wang, Yixuan Li, Yanhong Zeng, Yuwei Guo, Dahua Lin, Tianfan Xue, Bo Dai. ICCV, 2025 arXiv We use identity-specific embeddings and structural learning with depth/surface-normal cues to handle complex multi-person interactions in human-centric video generation from a single image. We also contribute a dataset expansion with 25K multi-human interaction videos. |
|
|
Direct Numerical Layout Generation for 3D Indoor Scene Synthesis via Spatial Reasoning
Xingjian Ran, Yixuan Li, Linning Xu,Mulin Yu, Bo Dai. NeurIPS, 2025 paper / project page We introduce DirectLayout, a framework that directly generates numerical 3D layouts from text descriptions, without relying on intermediate representations and constrained optimization. The model employs Chain-of-Thought reasoning and design CoT-Grounded Generative Layout Reward to enhance spatial planning and generalization. Extensive experiments demonstrate that DirectLayout achieves impressive semantic consistency, generalization and physical plausibility. |
|
|
Proc-GS: Procedural Building Generation for City Assembly with 3D Gaussians
Yixuan Li, Xingjian Ran, Linning Xu,Tao Lu, Mulin Yu Zhenzhi Wang, Yuanbo Xiangli, Dahua Lin, Bo Dai. CVPR Workshop on Urban Scene Modeling, 2025, Spotlight paper / project page / code Proc-GS combines procedural modeling with 3D Gaussian Splatting, enabling efficient generation of diverse buildings with high rendering quality. This integration allows scalable city creation with precise control for both real and synthetic scenarios. |
|
|
HumanVid: Demystifying Training Data for Camera-controllable Human Image Animation
Zhenzhi Wang, Yixuan Li, Yanhong Zeng, Youqing Fang, Yuwei Guo, Wenran Liu, Jing Tan, Kai Chen, Tianfan Xue, Bo Dai, Dahua Lin. NeurIPS (Datasets and Benchmarks Track), 2024 arXiv / homepage / code We propose camera-controllable human image animation task for generating video clips that are similar to real movie clips. To achieve this, we collect a dataset named HumanVid, and a baseline model combined by Animate Anyone and CameraCtrl. Without any tricks, we show that a simple baseline trained on our dataset could generate movie-level video clips. |
|
|
MatrixCity: A Large-scale City Dataset for City-scale Neural Rendering and Beyond
Yixuan Li*, Lihan Jiang*, Linning Xu,Yuanbo Xiangli, Zhenzhi Wang, Dahua Lin, Bo Dai. ICCV, 2023 paper / project page / code A large scale synthetic dataset from Unreal Engine 5 for city-scale NeRF rendering. |
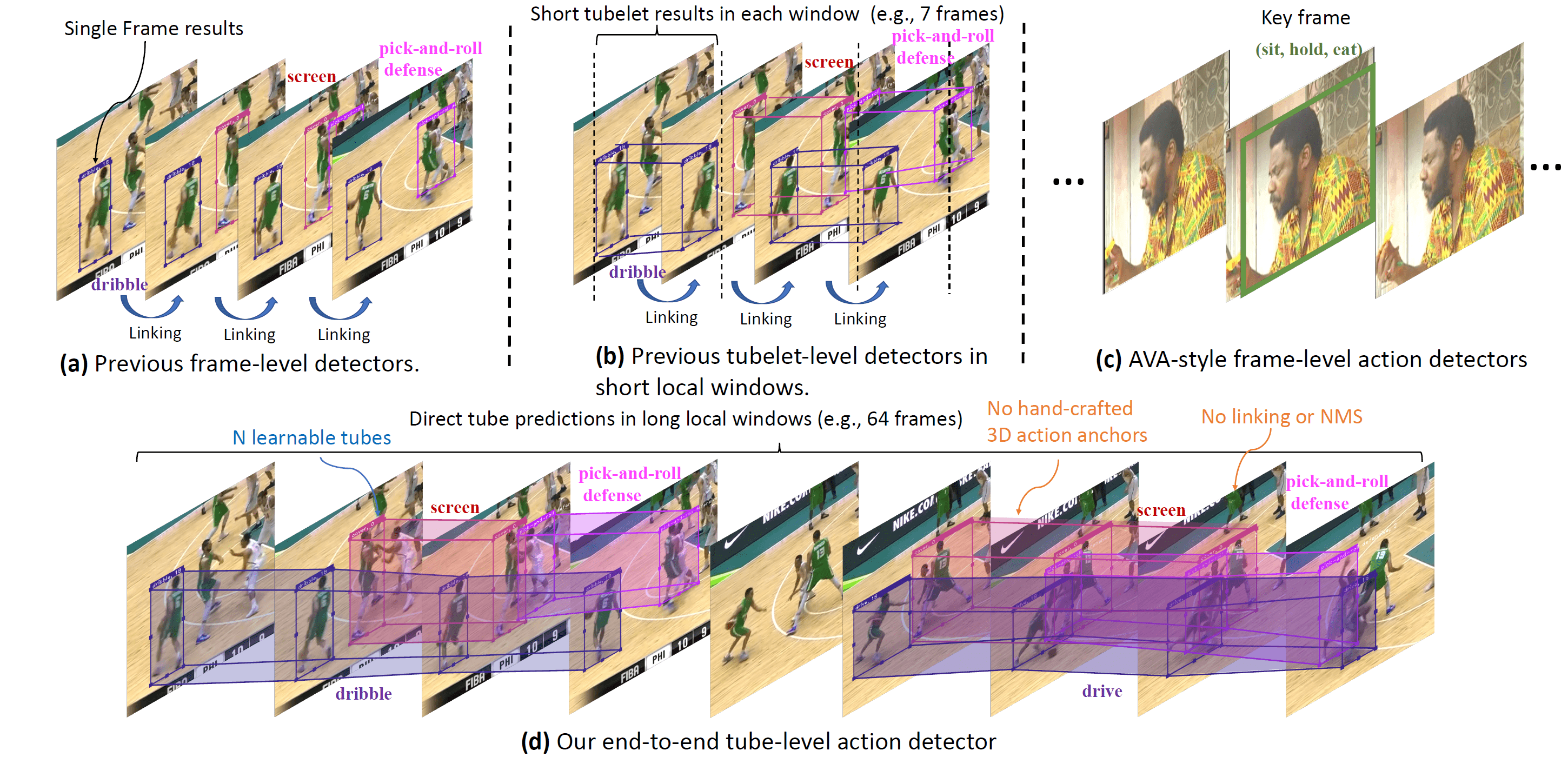 |
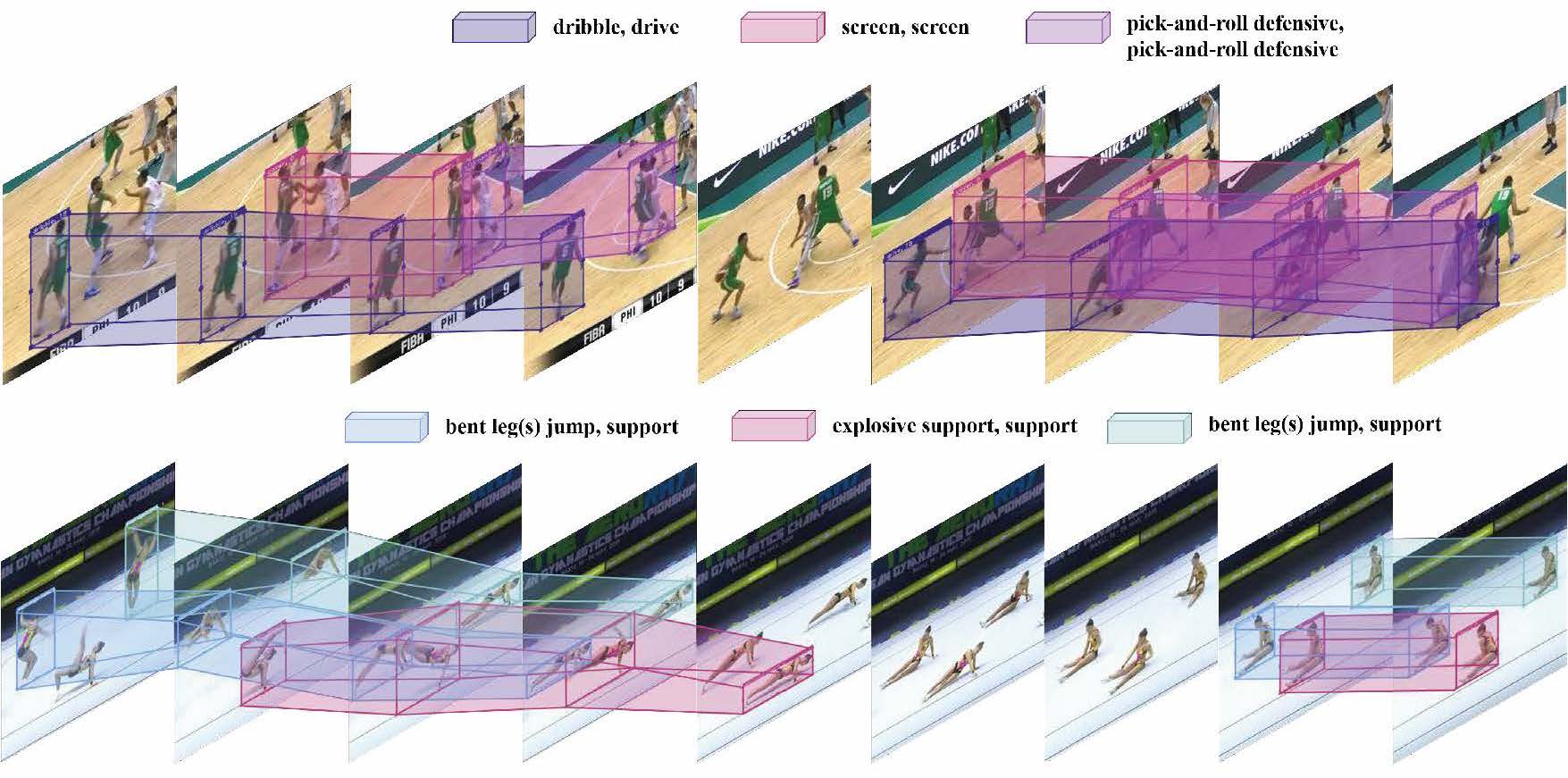
Sparse Action Tube Detection
Yixuan Li*, Zhenzhi Wang*, Zhifeng Li, Limin Wang. TIP, 2024 paper We present a simple end-to-end action tube detection method, which reduces the dense hand-crafted anchors, captures longer temporal information and explictly predicts the action boundary. |
 |
MultiSports: A Multi-Person Video Dataset of Spatio-Temporally Localized Sports Actions
Yixuan Li, Lei Chen, Runyu He, Zhenzhi Wang, Gangshan Wu, Limin Wang. ICCV, 2021 one track of ICCV2021, ECCV2022 Workshop DeeperAction. paper / code A fine-grained and large-scale spatial-temporal action detection dataset with 4 different sports, 66 action categories. |
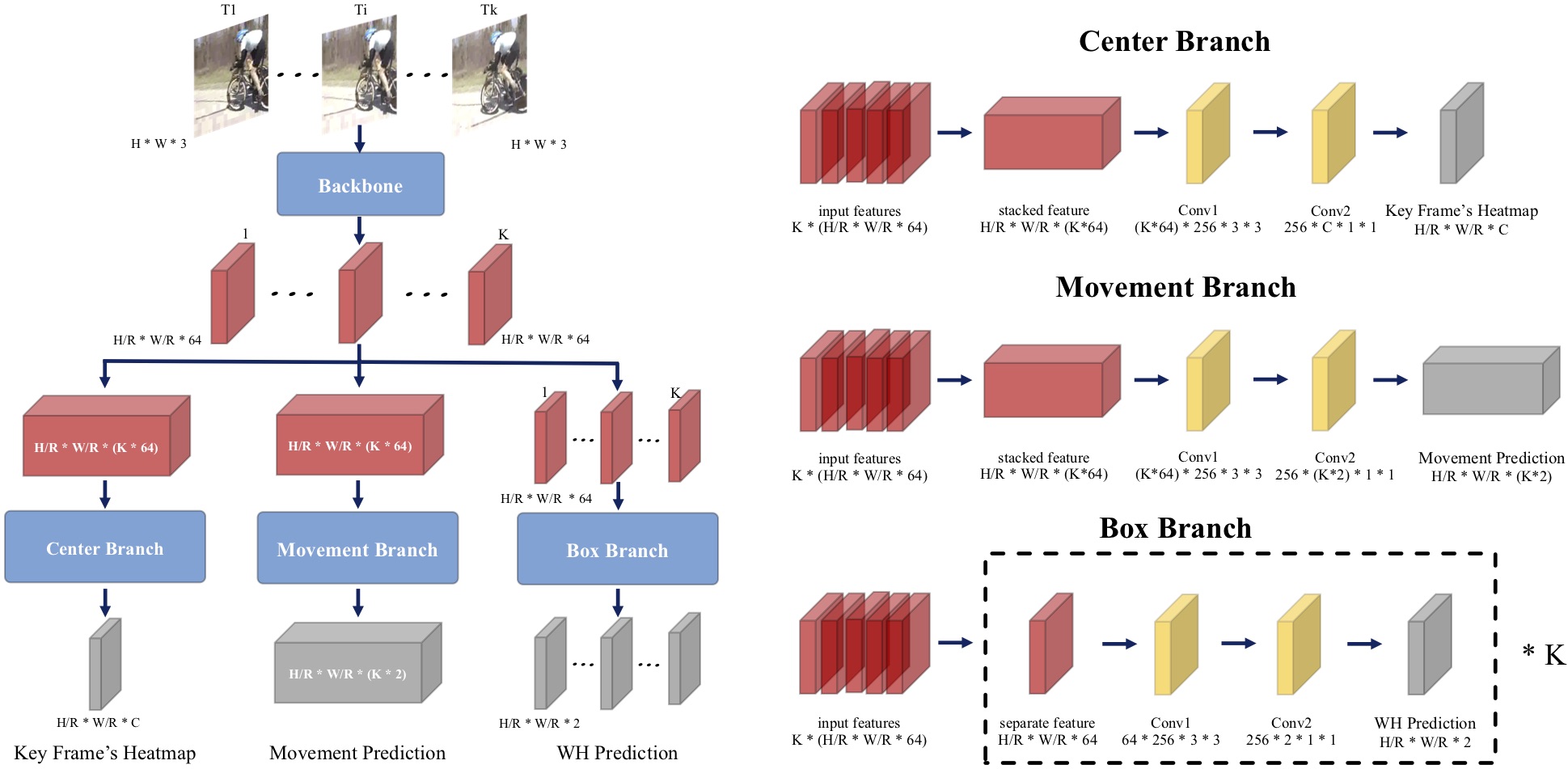 |
Actions as Moving Points
Yixuan Li*, Zixu Wang*, Limin Wang, Gangshan Wu. ECCV, 2020 paper / code A conceptually simple, computationally efficient, and more precise anchor-free action tubelet detector. |
Professional Services
• Conference reviewer for CVPR, ICCV, ECCV, NeurIPS. |
|
Thanks Jon Barron for sharing the source code of this website template. |